시스템 인프라 관련 개발을 진행하다 보니 수많은 성능 측정 데이터들을 어떻게 하면 보기 좋게 정리할 수 있을지 고민이 많다. 일반적으로 이런 일에 가장 많이 사용하는 도구는 당연히 스프레드시트다. 스프레드시트의 대명사 엑셀은 응용범위가 넓고, 간단한 수식과 함수를 이용해 다양한 결과물을 도출해 낼 수 있는 강력한 데이터 처리 도구이다. 많은 회사에서 사용하고 있어 손쉽게 접할 수 있기도 하다. 그러나 범용이기 때문에 원하는 결과를 만들기 위해서는 품이 많이 들 수밖에 없다.
최근 진행한 디스크의 성능을 측정하는 업무를 복기해 보았다. 결과의 정확도를 높이기 위해 반복 실험을 진행하여 1,500개의 결과를 얻었다. 결과 파일에는 필요한 메트릭만 있는 것이 아니므로 원하는 값을 선택해 엑셀 시트에 입력해야 했다. 1,500개의 결과 파일을 일일이 열어 원하는 메트릭을 뽑아 시트에 입력하는 것은 말도 안 되는 중노동이었기 때문에, bash script를 이용해 필요한 메트릭만을 추출해 tsv 파일을 만들어냈다. 이 파일을 엑셀에서 읽어 들여 시트에 입력하고, 각 메트릭의 통계를 위한 수식들을 만들었다. 그리고 별도로 그래프를 생성했다. 어렵지 않은 작업이지만 반복되는 일들이 있어 생각보다 많은 시간이 걸렸다. 필요한 통계치를 도출하기 위해 알고 있어야 하는 함수와 옵션들도 많고, 확률분포 그래프라도 그리려면 더 많은 작업을 해야 한다.
이런 일을 쉽고 빠르게 하는 방법이 없을까? SAS나 SPSS와 같은 통계 전용 프로그램을 사용하면 어떨까? 아니면 수치 해석용 프로그램인 MATLAB은? 모두 진입장벽이 높은 도구들이다. 게다가 비싸기까지 하다.
하지만 R이 출동하면 어떨까?
![]()
R은 통계와 그래프를 위한 오픈소스 프로그래밍 언어이다. 다양한 통계 기법과 수치 해석 기법을 제공하며 사용자 제작 패키지를 추가하여 기능 확장도 가능하다.
일단 R의 프로젝트 사이트(https://cran.r-project.org)에서 제공하는 문서를 찾아보았다. 문서를 열자 영문 스크립트가 방대하게 펼쳐진다. 당장 필요한 것은 최대/최솟값과 중간값, 평균값 그리고 테스트 조건별 확률분포 그래프 정도인데 전체 문서를 정독하며 학습할 필요는 없을 것 같다. 필요한 내용만 체리피킹 해보자.
설치
R은 Windows, macOS, Linux를 모두 지원한다. 웹페이지를 참조하면 쉽게 설치할 수 있다.
- Windows
- 웹페이지에서 제공하는 인스톨러를 다운로드하여 설치한다.
- macOS
- Linux
- apt를 이용해 쉽게 설치할 수 있다.
$ sudo apt-get install r-base
- apt를 이용해 쉽게 설치할 수 있다.
실행
Unix 계열에서는 터미널을 열고 R을 입력하면 인터프리터가 실행된다. 윈도에서는 설치 후 생성된 R 아이콘을 클릭하면 GUI 콘솔이 실행된다. Mac에서도 GUI 콘솔을 사용할 수 있다.
$ R
R version 3.5.2 (2018-12-20) -- "Eggshell Igloo"
Copyright (C) 2018 The R Foundation for Statistical Computing
Platform: x86_64-apple-darwin18.2.0 (64-bit)
R은 자유 소프트웨어이며, 어떠한 형태의 보증없이 배포됩니다.
또한, 일정한 조건하에서 이것을 재배포 할 수 있습니다.
배포와 관련된 상세한 내용은 'license()' 또는 'licence()'을 통하여 확인할 수 있습니다.
R은 많은 기여자들이 참여하는 공동프로젝트입니다.
'contributors()'라고 입력하시면 이에 대한 더 많은 정보를 확인하실 수 있습니다.
그리고, R 또는 R 패키지들을 출판물에 인용하는 방법에 대해서는 'citation()'을 통해 확인하시길 부탁드립니다.
'demo()'를 입력하신다면 몇가지 데모를 보실 수 있으며, 'help()'를 입력하시면 온라인 도움말을 이용하실 수 있습니다.
또한, 'help.start()'의 입력을 통하여 HTML 브라우저에 의한 도움말을 사용하실수 있습니다
R의 종료를 원하시면 'q()'을 입력해주세요.
>
데이터 읽어들이기
사용할 데이터는 worker의 개수를 10에서 250까지 변경하며 각 케이스의 bandwidth를 30회 반복 측정한 결과다. bash script를 이용해 다음과 같은 포맷의 tsv 파일을 만들었다.
$ cat result.tsv
worker bandwidth
010 370.4
020 356.4
030 291.2
040 162.4
050 166.9
060 160.0
070 156.2
080 243.3
090 275.0
100 258.6
...
이 파일을 R에서 읽기 위해서는 read.table() 함수를 사용하면 된다.
> result <- read.table('./result.tsv', header=TRUE, sep='\t')
> result
worker bandwidth
1 10 370.4
2 20 356.4
3 30 291.2
4 40 162.4
5 50 166.9
6 60 160.0
7 70 156.2
8 80 243.3
9 90 275.0
10 100 258.6
...
read.table() 함수에는 수 많은 옵션이 있지만, 예제에서 사용한 정도만 알면 csv, tsv 파일은 쉽게 읽을 수 있다.
header=TRUE- TRUE이면 파일의 첫 줄을 header로 사용한다.
- FALSE이면 자동으로 V1, V2… 형태의 컬럼 이름이 붙는다.
- default 값은 FALSE이다.
sep='\t'- 컬럼 구분할 구분자를 설정한다.
- csv의 경우 tab 문자 대신 comma를 지정해주면 된다.
- default 값은 하나 이상의 white space이다. space와 tab의 경우 구분자를 지정하지 않아도 된다.
이제 result라는 데이터셋 객체에 tsv 파일의 데이터가 로드되었다. read.table() 함수 외에도 읽을 파일 포맷에 따라 read.csv(), read.delim() 등의 함수를 사용할 수도 있다. read.csv()는 header=TRUE, sep=',', read.delim()는 header=TRUE, sep='\t'가 default 옵션이다.
통계치 얻기
전술했지만 필요한 통계치는 최대/최솟값과 중간값, 평균값이다. 엑셀에서는 각각 수식을 작성하고 범위를 지정하면 얻을 수 있는 값들이다. R을 이용하면 더 간단하고 빠르게 모든 값을 얻을 수 있다. 요약 통계를 출력하는 summary() 함수를 제공하기 때문이다.
> bw <- result$bandwidth # result 데이터셋의 bandwidth 컬럼 데이터를 bw 객체에 할당
> summary(bw)
Min. 1st Qu. Median Mean 3rd Qu. Max.
156.2 263.2 280.3 284.3 297.3 383.3
예제는 result 데이터셋의 bandwidth 컬럼이 가진 모든 값을 대상으로 최대/최솟값, 1사/3사분위값, 중간값, 평균값을 계산해 출력해준다. 엑셀처럼 각각의 함수를 이용해 계산할 수도 있다. min(), max(), median(), mean() 등의 함수를 이용하면 된다.
summary()와 유사한 fivenum(), quantile() 함수도 제공되는데, 평균값을 제외한 나머지 값들을 출력해준다. 다만 quantile() 함수는 확률적으로 균등하게 자른 값을 출력해주기 때문에 summary()나 fivenum()의 출력값과 결과가 다를 수 있다.
> fivenum(bw)
[1] 156.20 263.15 280.30 297.35 383.30
> quantile(bw)
0% 25% 50% 75% 100%
156.200 263.225 280.300 297.325 383.300
이 밖에도 통계하면 떠오르는 분산, 표준편차를 계산해주는 함수도 제공한다. 각각 var()와 sd() 함수다.
> var(bw)
[1] 1451.567
> sd(bw)
[1] 38.09944
이처럼 R이 기본 제공하는 함수들을 이용하여 간단하게 필요한 통계치들을 모두 얻을 수 있다.
그래프 그리기
통계치를 얻었으니 이제 확률분포 그래프를 그릴 차례다. 확률분포 그래프는 셀을 잘게 잘게 쪼갠 히스토그램을 이용해 그린다고 배웠던 것 같은 느낌적 느낌이 기억 저편에 흐릿하다. 일단 그려보자. 히스토그램은 hist() 함수를 이용하여 그릴 수 있다.
> hist(bw, breaks=100, probability=TRUE)
breaks=100- 히스토그램 셀의 개수
- 숫자가 커질수록 선형에 가까워진다.
- default 값은 10
probability=TRUE- Y축을 출현 확률로 지정
- FALSE인 경우, Y축은 출현 빈도를 나타낸다.
- default 값은 FALSE
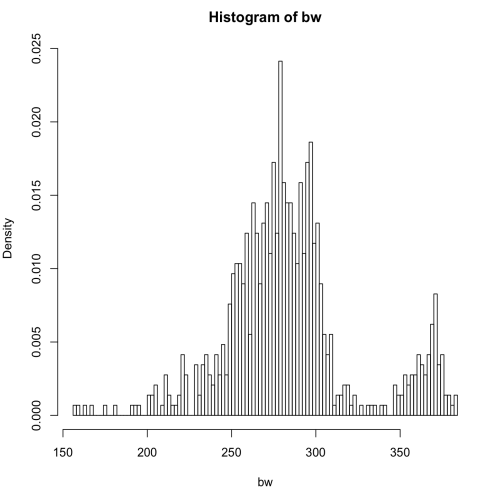
가운데가 불룩한 정규분포도에 정확히 부합하지는 않지만 비슷한 결과가 나오기는 했다. 정규분포도와 다른 이유는 데이터셋의 문제다. worker의 개수를 10에서 250까지 변경하며 bandwidth를 반복 측정했던 데이터이기 때문에 worker 개수 별 분포가 섞여 있는 결과가 나온 것이다. 정확한 그래프를 얻기 위해서는 worker의 개수를 각각의 집단으로 하는 집단별 히스토그램을 그려야 한다.
25개의 히스토그램을 그리자니 몹시 귀찮다. 한꺼번에 그릴 수는 없을까? 물론 방법은 있다.
박스플롯(boxplot)
박스플롯은 fivenum() 또는 quantile() 함수로 얻을 수 있는 5가지 통계치(최솟값, 1사분위값, 중간값, 3사분위값, 최댓값)을 이용해 그리는 상자 형태의 그래프다. 히스토그램과는 다르게 집단이 여러 개인 경우에도 하나의 그래프에 표현할 수 있다. R에서는 박스플롯 그래프를 그리기 위해 boxplot() 함수를 제공한다.
> worker <- report$worker # result 데이터셋의 worker 컬럼 데이터를 worker 객체에 할당
>
> boxplot(bw~worker, ylim=c(0, 400), xlab=~Workers, ylab=Bandwidth~MB/s)
>
> grid() # 그래프에 grid 표시
bw~worker- y~grp, 그룹별 numeric vector를 나타내는 수식
- worker의 개수 별 그룹을 만들고 각각의 bandwidth를 입력하겠다는 의미
ylim=c(0, 400)- y축의 범위를 0에서 400으로 설정
xlab,ylab- x축과 y축의 label 설정
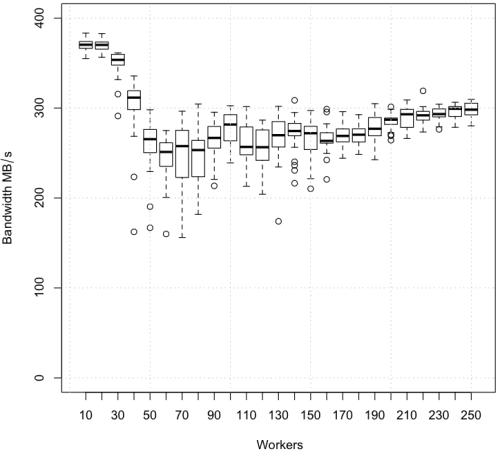
이상한 그래프가 그려졌다. 그래프만 봐서는 무슨 의미인지 잘 모르겠다. 좀 더 자세히 알아보자.
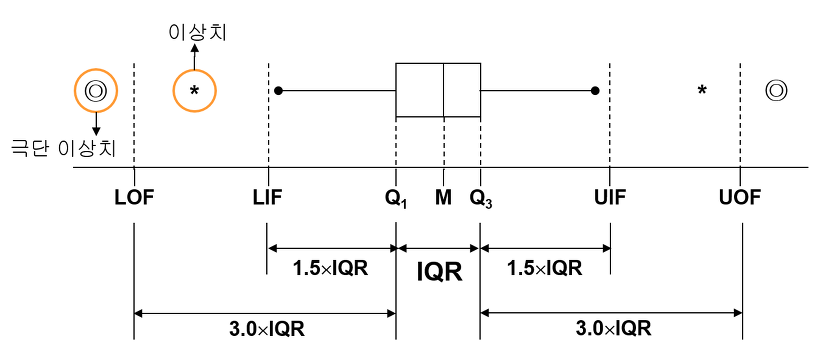
박스는 1사분위값과 3사분위값을 경계로 그려지며 박스 안의 선은 중간값이다. 박스는 전체 분포의 50%에 해당한다. LIF(minimum)와 UIF(maximum)는 각각 하한값 상한값을 나타내며 두 값의 사이는 전체 분포의 약 99%에 해당한다. LIF와 UIF 밖의 값들은 이상 수치로 간주하고 통계에서는 제외한다.
이를 정규분포도와 비교해보면 각각의 박스플롯은 그룹별 정규분포를 나타낸다는 것을 알 수 있다.
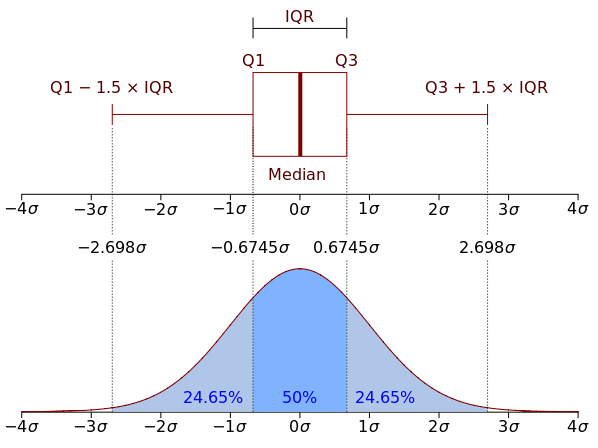
이런 그래프를 그려야 하는 이유가 무엇일까? 앞서 설명한 바와 같이, 이 그림은 worker 갯수 별 bandwidth의 정규분포를 박스플롯으로 나타낸 것이다. 즉, multi process 환경에서 디스크의 대략적인 bandwidth를 한눈에 쉽게 알아보기 위함이다.
앞의 박스플롯 그래프를 다시 보면 대부분의 박스가 250~300MB/s 사이에 분포한다는 것을 쉽게 알 수 있다. 따라서 이 디스크의 bandwidth는 대략 250~300 MB/s라 할 수 있다.
마치며…
… 확실히 확률과 통계는 어렵다. 배운지 20년이 다 되어가니 다시 공부해도 잘 모르겠다. 손으로 계산하는 것은 상상도 못 할 것 같다. 하물며 엑셀을 이용한다 하더라도 쉽지 않은 작업일 것이다. R은 이런 복잡한 계산을 순식간에 처리해준다. 필요한 내용만 빠르게 학습한 수준이지만, 앞으로 있을 여러 가지 성능측정 시험을 정리하는 데 유용하게 사용할 수 있을 것 같다.
